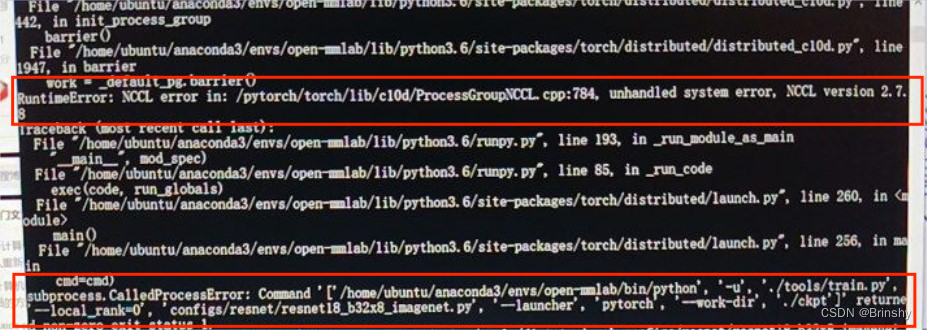
RuntimeError: NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL.
|
|
发现报错:
RuntimeError: NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL.cpp:784, unhandled system error
编辑想在linux上跑跑mmclassification中的resnet网络,但是报错,查阅资料后发现,第二个错误是由于第一个错误产生的。那么现在就要解决第一个报错。
第一个报错查阅了一堆资料后,发现是GPU使用数量的原因,但我电脑只有一个GPU,修改了配置文件后,依旧这样报错。有的博主是由于文件中有中文字符,我仔细检查后没有发现。
最后才发现,之前用的训练命令如下:- sh ./tools/dist_train.sh configs/resnet/resnet18_b32x8_imagenet.py 1 --work-dir ./ckpt
dist_train.sh – 训练 sh 脚本
configs/resnet/resnet18_b32x8_imagenet.py – 训练依赖的配置
1 – GPU 个数
--work-dir ./ckp – 模型存放的路径
但是这个命令只适用于多个GPU的时候,单个GPU得用以下命令:- python ./tools/dist_train.sh configs/resnet/resnet18_b32x8_imagenet.py --work-dir ./ckpt
编辑
来源:https://www.cnblogs.com/Brinshy/p/17233345.html
免责声明:由于采集信息均来自互联网,如果侵犯了您的权益,请联系我们【E-Mail:cb@itdo.tech】 我们会及时删除侵权内容,谢谢合作! |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
x
|
|
|
|
|
发表于 2023-3-19 15:55:00
举报
回复
分享
|
|
|
|
|