|
|
某大厂面试题1
1. 分布式事务的一致性问题
事务的四大特性(ACID)
原子性(Atomicity):一个事务(transaction)要么没有开始,要么全部完成,不存在中间状态。
一致性(Consistency):事务的执行不会破坏数据的正确性,即符合约束。
隔离性(Isolation):多个事务不会相互破坏。
持久性(Durability):事务一旦提交成功,对数据的修改不会丢失。
其中原子性、持久性、隔离性都是为了保证一致性的。
事务型数据库必须要解决的问题是数据的一致性问题。这里的一致性指的是ACID中的C,如果不满足C,会有多种数据异常,如脏读、不可重复读、幻读、读偏序、写偏序等数据异常。隔离性这一特性的出现就是为了解决一类由于并发事务而导致的数据不一致问题。
举例:
用户通过手机支付购买商家的商品,在支付过程中需要在一系列的系统进行处理:支付系统中需要创建支付单,在账务系统进行用户余额扣减,随后通知上游系统完成支付。在这个支付过程中,三种系统之间需要严格保证一致性。不能出现支付单成功但是余额没扣,也不能出现余额扣除后商家不发货的情况。
分布式系统属于异步系统(Asynchronous system model):不同进程的处理器速度可能差别很大,时钟偏移可能很大,消息传播延迟可能很大(可能很大意味着没有最大值限制)。这样就带来一个很大的问题:超时。超时一定有可能发生,但是超时又无法判断究竟是成功还是失败了,导致整个业务状态异常。而单台计算机属于同步系统(Synchronous system model),即使不同进程的处理器速度差异、时钟偏移延迟、消息延迟都有最大值的。
CAP理论
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
- Consistency 一致性:每次读取获得的都是最新写入的数据,即写操作之后的读操作,必须返回该值
- Availability 可用性:服务在正常响应时间内一直可用,返回的状态都是成功
- Partition-tolerance 分区容错性:即使遇到某节点或网络故障的时候,系统仍能够正常提供服务
尽管CAP狭义上针对的是分布式存储系统,但它一样可以应用于普遍的分布式系统。由于分区容错性(P)是分布式系统最重要的特点,因此CAP可以理解为:当网络发生分区(P)时,要么选择C一致性,要么选择A可用性。
举例来说,具体到上文描述的用户支付的例子中,当网络存在异常时,要么用户可能暂时无法支付,要么用户的余额可能不会立刻扣减。这两种选择就是在架构设计中对可用性和一致性的权衡。
2. 堆排序
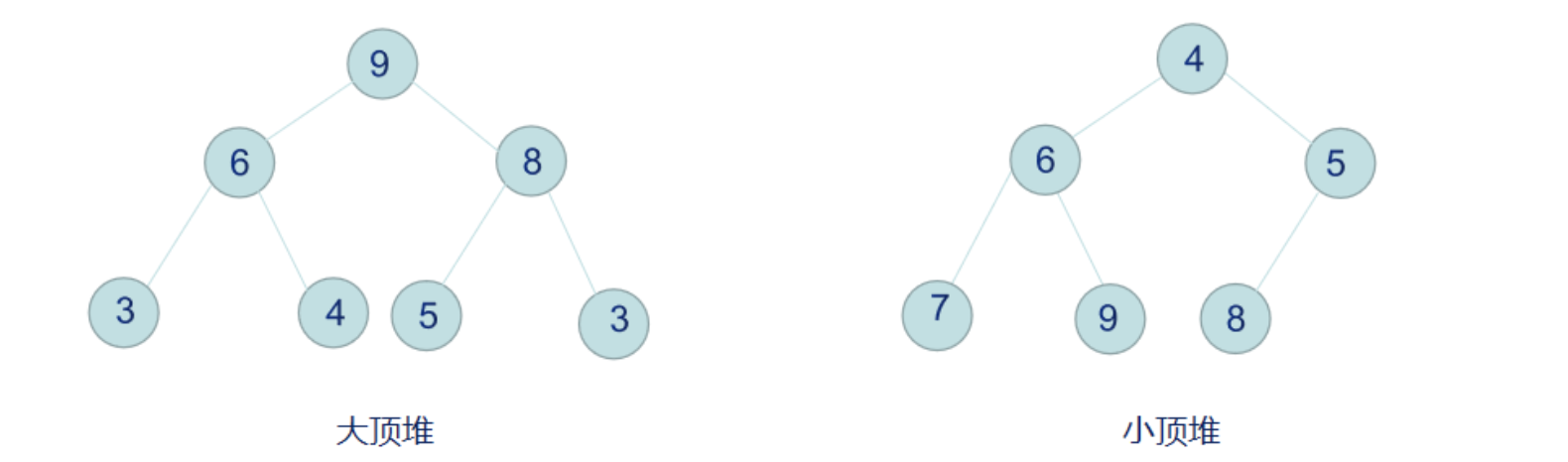
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。复杂度是O(nlogn)
堆排序是利用堆这种数据结构所设计的一种排序算法。堆实际上是一个完全二叉树结构。问:那么什么是完全二叉树呢?答:假设一个二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
- 小顶堆满足: Key[i] <= key[2i+1] && Key[i] <= key[2i+2]
- 大顶堆满足: Key[i] >= Key[2i+1] && key >= key[2i+2]每个结点的值都大于或等于其左右孩子的值
步骤
- 将待排序的数组初始化为大顶堆,该过程即建堆。
- 将堆顶元素与最后一个元素进行交换,除去最后一个元素外可以组建为一个新的大顶堆。
- 由于第二步堆顶元素跟最后一个元素交换后,新建立的堆不是大顶堆,需要重新建立大顶堆。重复上面的处理流程,直到堆中仅剩下一个元素。
假设我们有一个待排序的数组 arr = [4, 6, 7, 2, 9, 8, 3, 5], 我们把这个数组构造成为一个二叉树,如下图:
此时9跟4交换后,4这个节点下面的树就不是不符合大顶堆了,所以要针对4这个节点跟它的左右节点再次比较,置换成较大的值,4跟左右子节点比较后,应该跟6交换位置。
那么至此,整个二叉树就是一个完完整整的大顶堆了,每个节点都不小于左右子节点。此时我们把堆的跟节点,即数组最大值9跟数组最后一个元素2交换位置,那么9就是排好序的放在了数组最后一个位置。
2到了跟节点后,新的堆不满足大顶堆,我们需要重复上面的步骤,重新构造大顶堆,然后把大顶堆根节点放到二叉树后面作为排好序的数组放好。就这样利用大顶堆一个一个的数字排好序。
值得注意的一个地方是,上面我们把9和2交换位置后,2处于二叉树根节点,2需要跟右子树8交换位置,交换完位置后,右子树需要重新递归调整大顶堆,但是左子树6这边,已经是满足大顶堆属性,因为不需要再操作。
[code]class Solution(object): def heap_sort(self, nums): i, l = 0, len(nums) self.nums = nums # 构造大顶堆,从非叶子节点开始倒序遍历,因此是l//2 -1 就是最后一个非叶子节点 for i in range(l // 2 - 1, -1, -1): self.build_heap(i, l - 1) # 上面的循环完成了大顶堆的构造,那么就开始把根节点跟末尾节点交换,然后重新调整大顶堆 for j in range(l - 1, -1, -1): nums[0], nums[j] = nums[j], nums[0] self.build_heap(0, j - 1) print("第{}轮堆排序:{}".format(l - j, nums)) return nums def build_heap(self, i, l): """构建大顶堆""" nums = self.nums left, right = 2 * i + 1, 2 * i + 2 ## 左右子节点的下标 large_index = i if left = pivot: j -= 1 lists=lists[j] while i < j and lists |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
x
|