一台虚拟机基于docker搭建大数据HDP集群的思路详解
|
|
前言
好多人问我,这种基于大数据平台的xxxx的毕业设计要怎么做。这个可以参考之前写得关于我大数据毕业设计的文章。这篇文章是将对之前的毕设进行优化。
个人觉得可以分为两个部分。第一个部分就是基础的平台搭建。例如Hadoop集群、Kafka集群。
第二个部分就是上层应用的建设,例如基于大数据平台的数据分析,以及大屏展示之类的可视化应用。前者提供了基础平台能力,让整个设计加入大数据元素;后者提供了上层应用能力,主要是让别人明白你利用大数据平台做了什么。
前些日子闲得无聊,在一台虚拟机上基于docker容器,使用Ambari搭建了一个HDP版本的Hadoop大数据集群。所以就结合这篇文章,对第一部分进行阐述,提供一个新的思路。
思路
在集群搭建的过程中,遇到了形形色色的问题。在问题里去思考、去查阅资料。这是一个蛮有意思的事情。
在上一篇文章也写了,我的大数据毕业设计的Hadoop平台搭建部分,是基于三台虚拟机实现的。当时使用的Apache版本的Hadoop。
Apache版本的缺点是没有一个统一的管控平台。
前期的安装需要在每个节点手动分发安装包、执行启动命令。后期的节点维护、服务启停都需要去后台执行命令。
加上三台虚拟机,每次启动费个老劲。所以我就寻思用Ambari来搭建一个HDP版本的、一个虚拟机就能搞定的、基于docker容器的Hadoop集群。
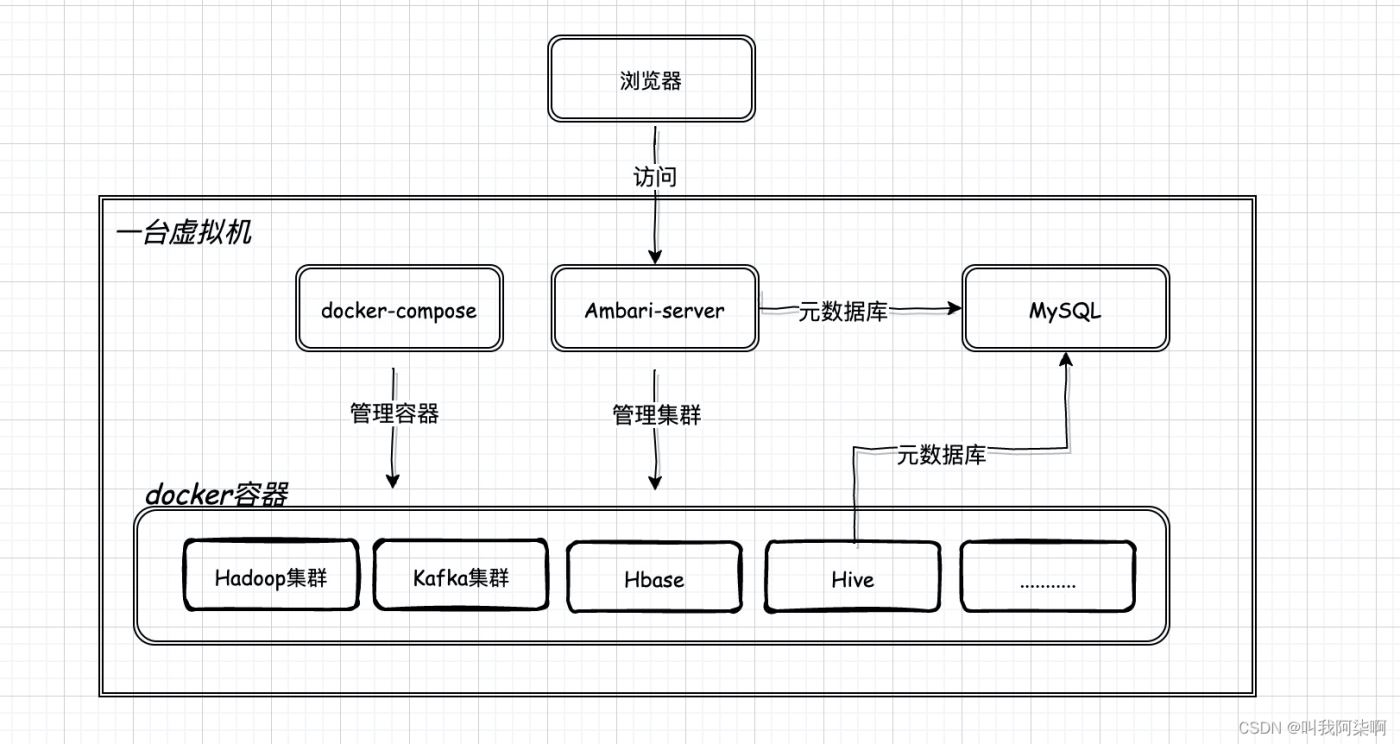
整体架构
整个架构设计和技术选型,都是根据个人需求选择,可以参考。
1. 技术选型
宿主机和docker的操作系统选择的是centos7。我尝试了centos8,不太行。主要
docker:容器,代替虚拟机节点搭建集群docker-compose:编排容器。对所有容器进行管理、启动Ambari:2.7.3版本。可视化安装、监控、管理所有集群。HDP:3.1版本。其中包括Hadoop、HDFS、Yarn、Spark、Kafka、Zookeeper等服务。MySQL:ambari元数据库。后面应用也会用到。
除此之外,还需要shell编写一些脚本。
2. 架构设计
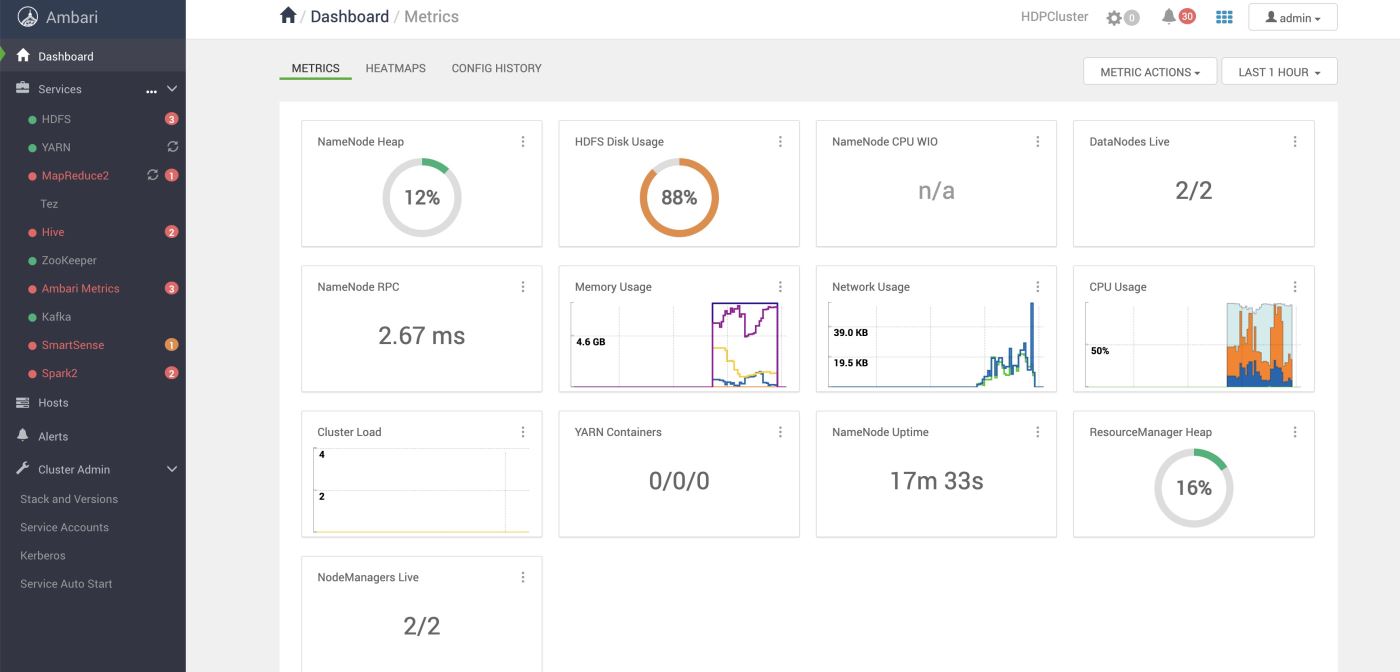
平台一览
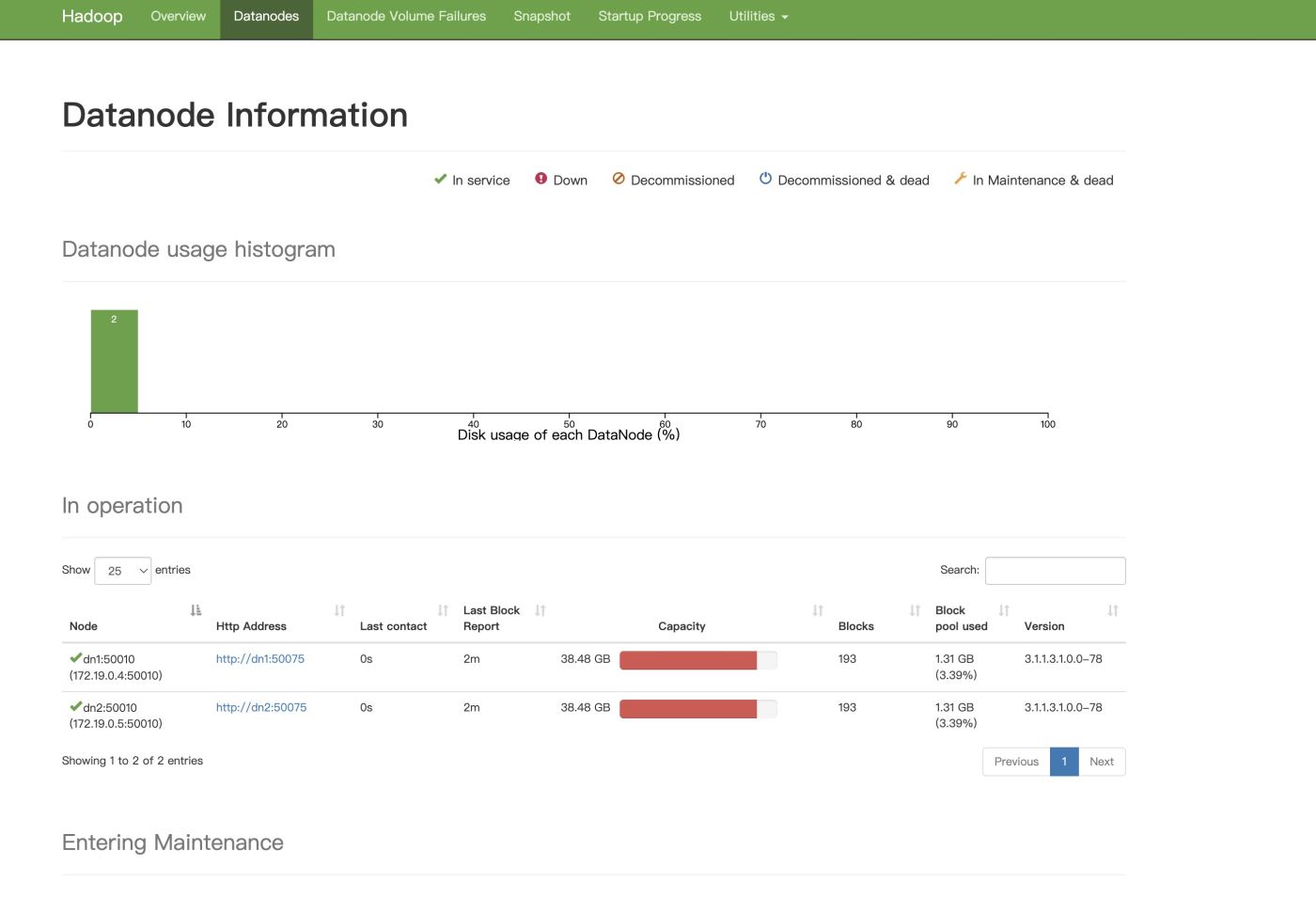
这就是Ambari的首页仪表盘的部分,里面可以看到HDFS的存储,内存使用量指标。
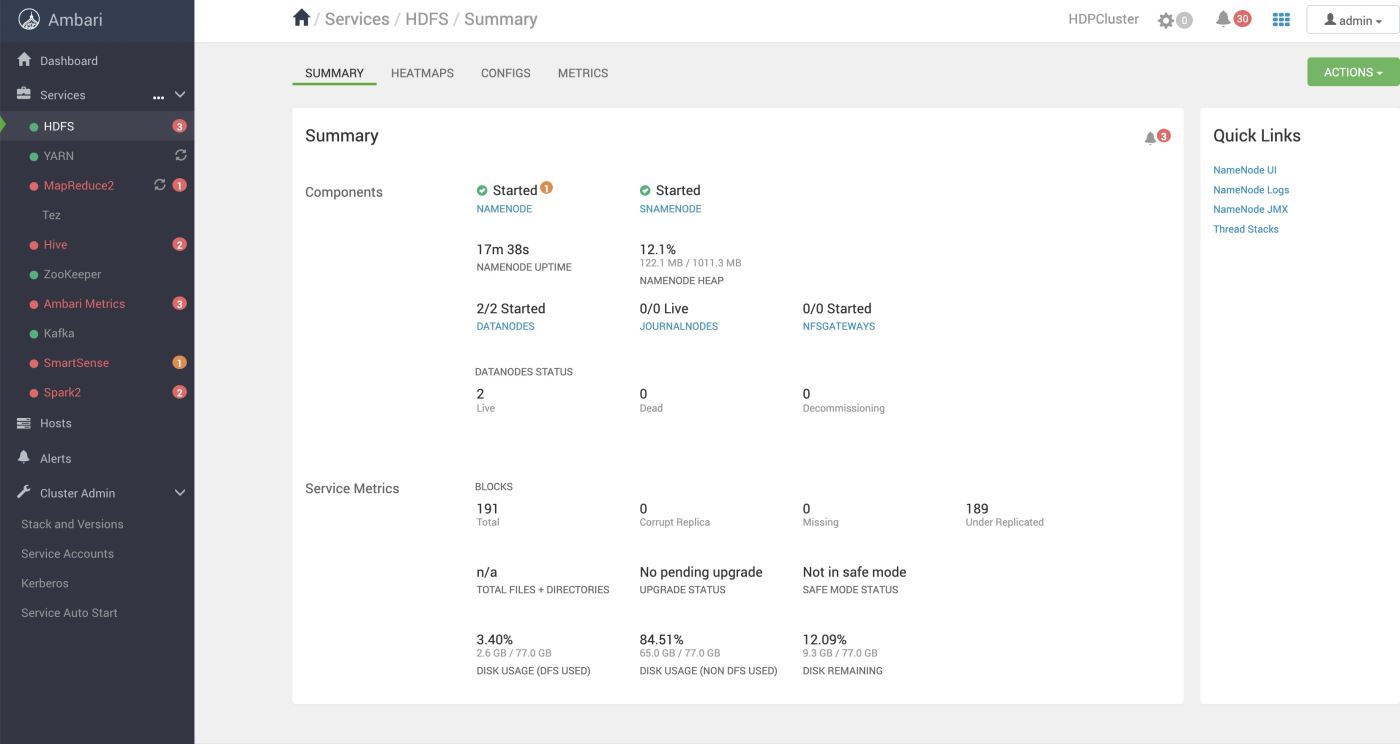
Hadoop集群
Hadoop集群一共用了四个节点。NameNode,一个备用的NameNode,两个DataNode。
点击右侧的NameNode UI可以看到Hadoop集群的UI界面。
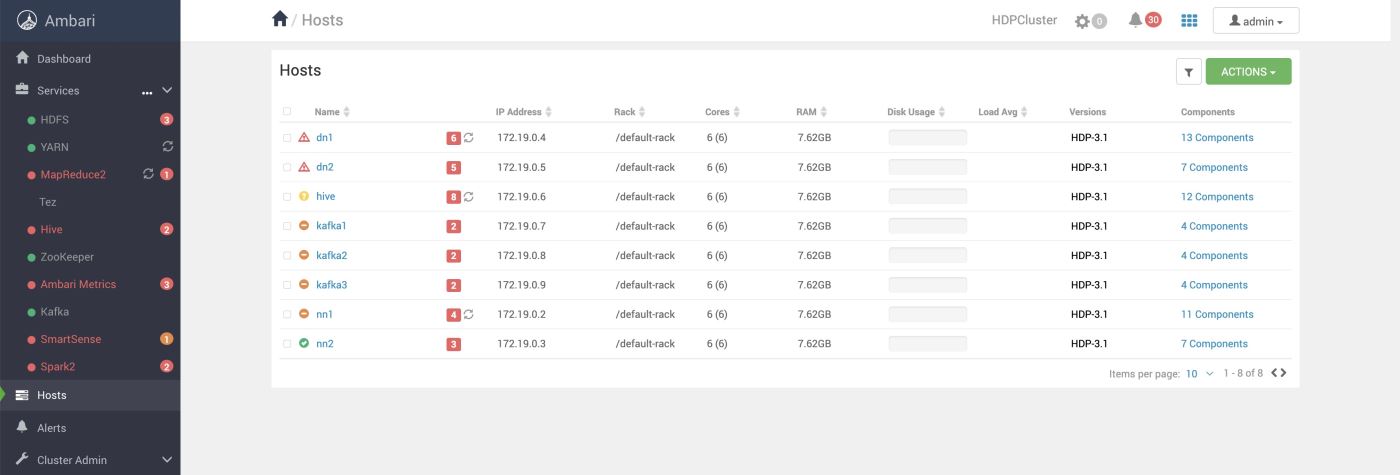
集群节点
这里的Hosts指的就是所有集群节点的个数,也是docker节点的个数。这里因为内存有限,所以一个docker启动了好几个服务。
例如这个kafka1节点,即安装了Kafka,又安装了Zookeeper。
环境准备
我在实践docker搭建集群的时候,90%的时间都花费在了环境准备上。同样,遇到的90%的问题也都在这个步骤上。
1. 虚拟机准备
我自己的架构是一台虚拟机,然后其他节点都是用docker代替的。docker你可以理解为轻量虚拟机。
我选择docker的理由:
觉得挺有意思,想挑战一下自己的软肋。*一个虚拟机可能需要占用20G存储,一个docker只占用几百MB**。只需要启动一台虚拟机即可。docker作为应用服务运行在这台虚拟机上。
其实,这里我是建议使用3 ~ 4台虚拟机的。因为docker本身对于很多人来说是有一定难度的,再加上需要将docker构建成节点,是需要花费很多时间的。
2. docker容器准备
如果说是头铁非要用docker,那么可以看看这一步。我在这一步构建节点docker镜像的时候,反复构建了很多次。
dockerfile
我们要自己编写dockerfile几月centtos7来构建docker容器的系统镜像。而且,docker容器代替了虚拟机,那么docker容器里的环境就要和虚拟机一样。所以dockerfile需要满足以下条件。
开放22端口,启动sshd服务配置jdk、scala生成密钥,配置ssh免密登录python2.7(centos7自带)yum安装一些软件,例如chrony等配置hosts
在编写dockerfile阶段,查阅了很多资料,反复构建,尝试了很多次才成功。
docker-compose
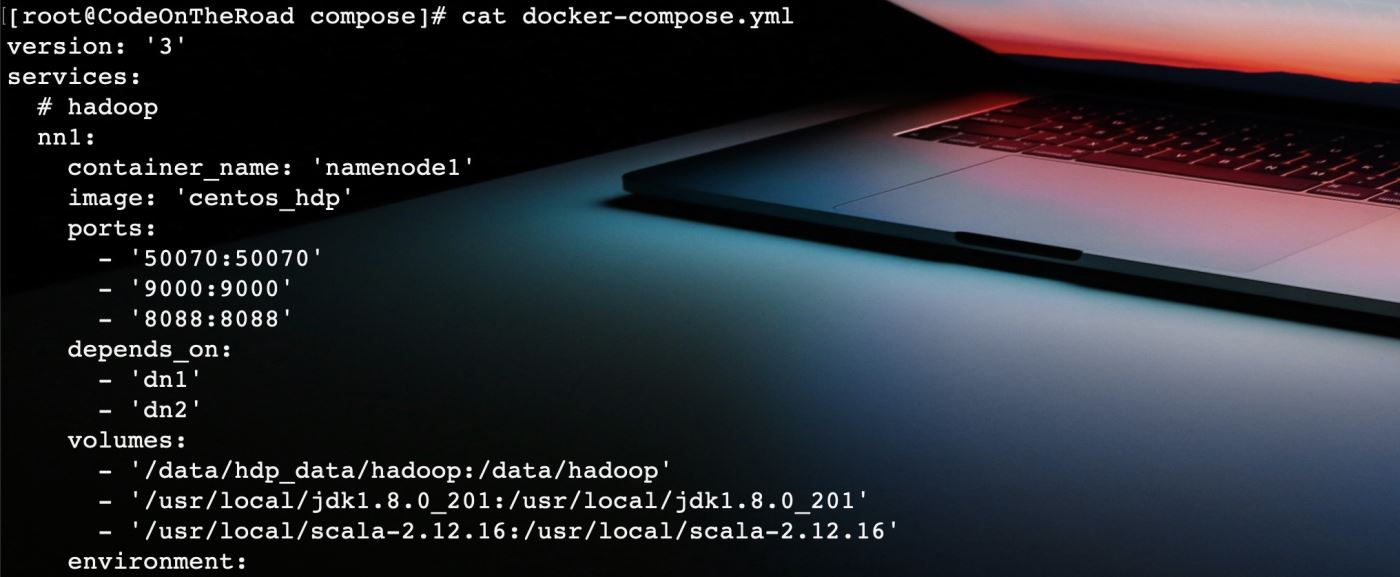
docker-compose是docker容器的编排工具,需要编写一个yaml配置文件,通过start/stop来启动/停止所有的容器。
这个centos_hdp就是我自己构建的镜像,ports来开放容器的端口,volumes来挂载宿主机的目录。
3. 下载安装包
我在2016年毕业设计中,所搭建的大数据平台的各个组件都是独立下载安装的。Hadoop的安装包需要去Hadoop官网下载,Kafka安装包需要去Kafka官网下载。想安装哪个版本就安装哪个版本。
基于Ambari安装,所有组件都包含在HDP安装包里,不过这个安装包挺大的,10G。- ambari-2.7.3.0-centos7.tar.gz
- HDP-3.1.0.0-centos7-rpm.tar.gz
- HDP-UTILS-1.1.0.22-centos7.tar.gz
- HDP-GPL-3.1.0.0-centos7-gpl.tar.gz
结语
本篇文章主要讲了大数据集群搭建的架构设计和实现思路部分,后面文章会探讨上层应用的构建。我现在自己也在学前端,想自己实现一些web应用。关于大数据集群搭建、后台实现以及前端技术,可以私我加群互相交流。
基于docker使用Ambari搭建Hadoop是有难度的,谨慎尝试。
到此这篇关于一台虚拟机基于docker搭建大数据HDP集群 的文章就介绍到这了,更多相关docker搭建HDP集群 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
来源:https://www.jb51.net/article/266463.htm
免责声明:由于采集信息均来自互联网,如果侵犯了您的权益,请联系我们【E-Mail:cb@itdo.tech】 我们会及时删除侵权内容,谢谢合作! |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
x
|
|
|
|
|
发表于 2023-1-2 10:32:24
举报
回复
分享
|
|
|
|
|