|
|
为什么要使用fiber,要解决什么问题?
在引入架构之前,react 会采用递归方法对比两颗虚拟DOM树,找出需要改动的节点,然后同步更新它们,这个过程称为reconcilation(协调)。在期间,会同步执行操作,提交到真实 DOM 的更改,会一直占着浏览器的资源,不能中断,中断后就不能恢复,使得我们一些用户操作定时器等等事件无法得到响应,是一个非常糟糕的用户体验。
所以我们要解决的问题就是:解决React主线程长时间占用的一个问题。 这个时候,就引入了架构。
fiber是什么?
可以理解为是一个执行单元,也可以理解为是一种数据结构。每一个React元素都对应一个fiber对象,我们先看看中的属性:
- function FiberNode(
- tag: WorkTag,
- pendingProps: mixed,
- key: null | string,
- mode: TypeOfMode,
- ) {
- // 作为静态数据结构的属性
- this.tag = tag; // Fiber对应组件的类型 Function/Class/Host...
- this.key = key; // key属性
- this.elementType = null; // 大部分情况同type,某些情况不同,比如FunctionComponent使用React.memo包裹
- this.type = null; // 对于 FunctionComponent,指函数本身,对于ClassComponent,指class,对于HostComponent,指DOM节点tagName
- this.stateNode = null; // Fiber对应的真实DOM节点
- // 用于连接其他Fiber节点形成Fiber树
- this.parent = null; // 指向父级Fiber节点
- this.child = null; // 指向子Fiber节点
- this.sibling = null; // 指向右边第一个兄弟Fiber节点
- this.index = 0;
- this.ref = null;
- // 作为动态的工作单元的属性 —— 保存本次更新造成的状态改变相关信息
- this.pendingProps = pendingProps;
- this.memoizedProps = null;
- this.updateQueue = null; // class 组件 Fiber 节点上的多个 Update 会组成链表并被包含在 fiber.updateQueue 中。 函数组件则是存储 useEffect 的 effect 的环状链表。
- this.memoizedState = null; // hook 组成单向链表挂载的位置
- this.dependencies = null;
- this.mode = mode;
- // Effects
- this.flags = NoFlags;
- this.subtreeFlags = NoFlags;
- this.deletions = null;
- // 调度优先级相关
- this.lanes = NoLanes;
- this.childLanes = NoLanes;
- // 指向该fiber在另一次更新时对应的fiber
- this.alternate = null;
- }
数据结构
React Fiber 就是采用链表实现的,主要就是通过以下这几个属性表示:
- this.parent = null; // 指向父级Fiber节点
- this.child = null; // 指向子Fiber节点
- this.sibling = null; // 指向右边第一个兄弟Fiber节点
- <div>
- <h1>
- <p>
- <a></a>
- </p>
- </h1>
- <h2></h2>
- </div>
每个元素都有这三个属性,观察上面图发现:
- :指向父级节点:
- :指向子节点
- :指向右边的兄弟节点
执行单元
我们可以把每个当做一个执行单元,每次执行完一个执行单元。会去检测还剩多少时间,如果没有时间就将控制权让给浏览器,如果还有时间就去执行下一个执行单元。
这里就涉及到了一个问题,如何和浏览器进行控制权的交接,浏览器何时空闲呢?。我们先来了解一下浏览器的工作:
浏览器工作:
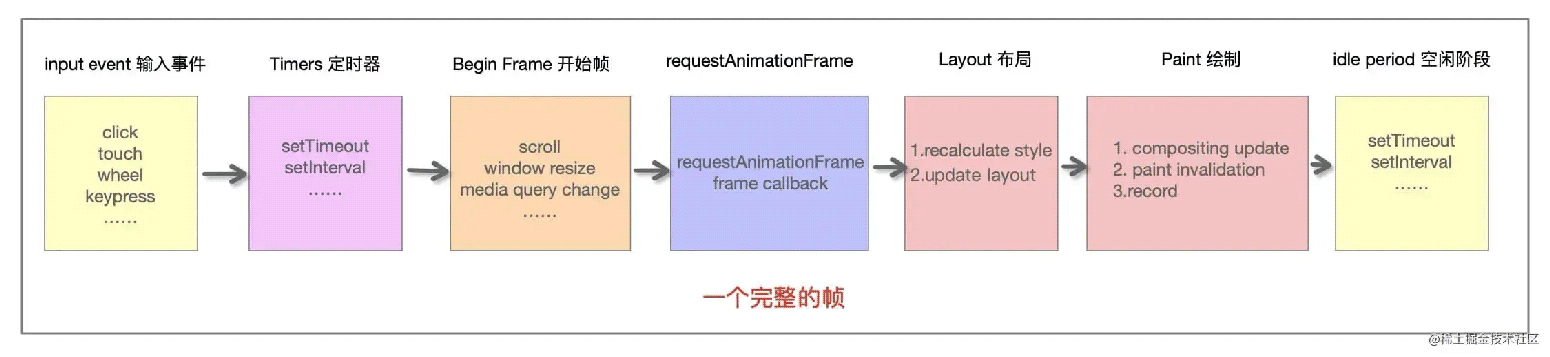
在浏览器中,我们所看到的页面是一帧一帧画出来的,渲染的帧率与设备的刷新率保持一致。通常情况下,我们的设备都是,也就是说,屏幕会刷新次。当每秒内绘制的帧数()超过时,页面渲染是流畅的,当帧数小于时,会明显感受到卡顿。下面来看完整的一帧中,浏览器具体做了哪些事情:
- 首先需要处理输入事件,能够让用户得到最早的反馈
- 接下来是处理定时器,需要检查定时器是否到时间,并执行对应的回调
- 接下来处理(开始帧),即每一帧的事件,包括、、等
- 接下来执行请求动画帧
- requestAnimationFrame(rAF
- 紧接着进行操作,包括计算布局和更新布局,即这个元素的样式是怎样的,它应该在页面如何展示
- 接着进行操作,得到树中每个节点的尺寸与位置等信息,浏览器针对每个元素进行内容填充
- 到这时以上的六个阶段都已经完成了,接下来处于空闲阶段(),可以在这时执行里注册的任务
这样我们把工作单元的任务放到回调当中,如果浏览器处理完上述的任务(布局和绘制之后),还有盈余时间,这个时候就可以执行我们的工作单元了。每次执行完一个执行单元。会去检测还剩多少时间,如果没有时间就将控制权让给浏览器。直至,和浏览器通过合作式调度完美配合,实现高性能应用。
Fiber执行原理
从根节点开始调度和渲染可以分为两个阶段:和。 先来了解下这几个关键名词:
workInProgress tree:
代表当前正在执行更新的树。在或者渲染 后,会构建一颗树,也就是,
currentFiber tree:
首次渲染之后,会生成一个对应于渲染的树,称之为 current 树。在新一轮更新时再重新构建,新的节点通过属性和的节点建立联系。
Effects list:
可以理解为是一个存储副作用列表容器。
render阶段:
在阶段中,会找到所有节点的变更,比如说节点新增,编辑,删除等等。这些变更称之为副作用effect。在这个阶段中,也可以认为是阶段,主要就是对比和之间的差异,然后打上。
在这个阶段,任务是可以终止的。React 可以根据当前可用的时间片处理一个或多个节点,并且得益于对象中存储的元素上下文信息以及构成的链表结构,使其能够将执行到一半的工作仍保存在内存的链表中。在重新获得控制权后,又可以根据保存在内存中的上下文信息快速找到停止的节点,然后继续工作执行工作单元。
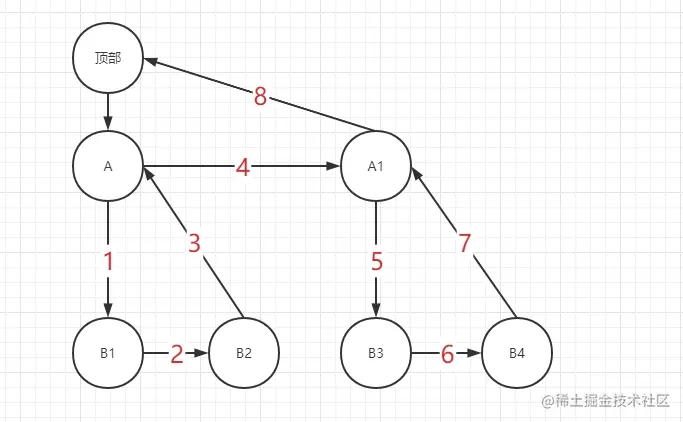
遍历节点过程:
遍历时采用的是后序遍历方法
- 从顶部开始遍历
- 如果有child节点,且还未遍历,遍历child节点
- 如果有child节点,且已经遍历过,则遍历sibling节点。
- 如果没有child节点,返回父节点
- 如果最后返回的节点为顶部,表示所有节点遍历完成。
收集effect list:
在遍历的过程中,我们会去收集所有变更的节点产出的,每个通过链表的方式链接。每个 fiber 有两个属性
- firstEffect:指向第一个有副作用的子fiber
- lastEffect:指向最后一个有副作用的子fiber
中间的使用做成一个单链表。
commit阶段:
与阶段不同,阶段是同步操作的。
为什么commit必须是同步的操作的?
因为在阶段是更新真实的,所以更新dom不可能一点一点去更新,这样用户体验会极差。所以阶段必须是同步执行,一次更新到位。
首先的事情是遍历列表,拿到每一个存储的信息,根据副作用类型执行相应的处理并提交更新到真正的。所有的都会在阶段之前被处理。当该阶段执行结束时,会被替换成。到这里,根据收集到的变更信息完成了刷新操作。
以上就是react fiber执行原理示例解析的详细内容,更多关于react fiber执行原理的资料请关注脚本之家其它相关文章!
来源:https://www.jb51.net/article/266670.htm
免责声明:由于采集信息均来自互联网,如果侵犯了您的权益,请联系我们【E-Mail:cb@itdo.tech】 我们会及时删除侵权内容,谢谢合作! |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
x
|