|
|
1.打开文件
位于自动导入的模块IO中,无需手动导入。- f = open('D:\M\test.txt')
- Traceback (most recent call last):
- File "d:\M\github\Python\Demo\t14.py", line 1, in <module>
- f = open('D:\M\test.txt')
- ^^^^^^^^^^^^^^^^^^^^^
- OSError: [Errno 22] Invalid argument: 'D:\\M\test.txt'
只指定文件名的话,会得到一个可读文件对象。若想写入文件,必须通过添加参数来指出。- 'r' 以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式。
- 'w' 以写入方式打开文件。如果文件存在则覆盖,如果文件不存在则创建一个新文件。
- 'a' 以追加模式打开文件。如果文件存在,则在文件末尾追加写入,如果文件不存在则创建一个新文件。
- 'x' 以独占方式创建文件,如果文件已经存在则返回 FileExistsError 错误。
- 'b' 以二进制模式打开文件。
- 't' 以文本模式打开文件(默认模式)。
- '+' 可读写模式(可与其他模式组合使用)。
- 默认模式为rt,将把文件视为Unicode文本,自动执行解码和编码,且默认使用UTF-8编码。
- 可以使用关键字参数encoding和errors。
- 若文件为声音图片视频之类的,可以使用二进制模式来禁用与文本相关的功能。、
2.文件的基本方法
2.1 读取和写入
f.write- f = open('test.txt', 'w')
- f.write('Hello')
- f.close # 记得关闭
- f = open('test.txt', 'r')
- str1 = f.read(4) # 读取前4个字符 指针到达第5个字符
- print(str1)
- str1 = f.read() # 从第五个字符开始读取
- print(str1)
- >
- Hell
- o
- f = open('test.txt', 'r')
- str1 = f.read(4)
- print(str1)
- f.seek(0) # 指针回溯
- str1 = f.read()
- print(str1)
- >
- Hell
- Hello
2.2.1 读取方法readline
可以不提供参数,读取一行后返回
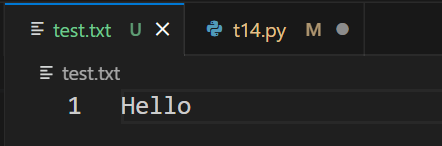
test.txt 文件内容为
注意:文件中每一行都有一个换行符,读取时,换行符也会被读取
- f = open('test.txt', 'r')
- str1 = f.readline()
- str2 = f.readline()
- print(str1)
- print(str2)
- f = open('test.txt', 'r')
- str1 = f.readline().strip()
- str2 = f.readline().strip()
- print(str1)
- print(str2)
- f = open('test.txt', 'r')
- str1 = f.readline(5)
- print(str1)
- > Hello
- f = open('test.txt', 'r')
- str1 = f.readlines()
- print(str1)
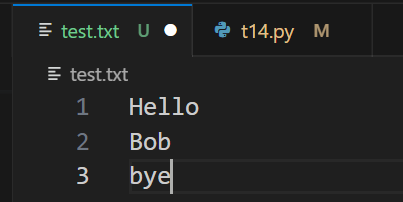
- > ['Hello\n', 'Bob\n', 'bye']
默认状态下,VSCode不会即时保存,需要先将test.txt保存,再运行程序
2.2.2 写入方法 writeline
先擦除所有内容,然后再写入
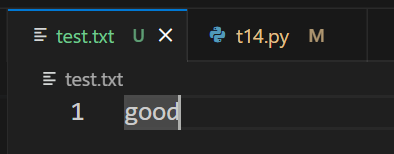
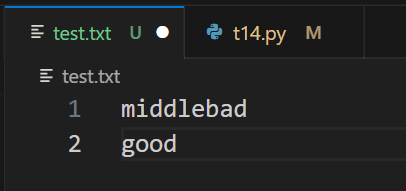
运行前,test.txt文件内容
- f = open('test.txt', 'w')
- f.writelines('good')
- f.close
写入时,不会自动添加换行符,需要自己添加,没有writeline方法,可以使用write- f = open('test.txt', 'w')
- f.write('middle')
- f.writelines('bad\n')
- f.writelines('good')
- f.close
2.3 记得关闭文件!
可以使用 try/finally 语句,再finally中调用close- try:
- f = open('test.txt', 'w')
- f.write('middle')
- f.writelines('bad\n')
- f.writelines('good')
- finally:
- f.close
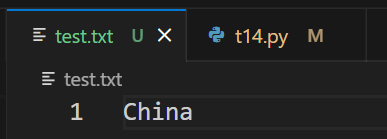
- # 将文件对象赋给test
- with open('test.txt', 'w') as test:
- test.write('middle')
3.迭代文件内容
3.1 每次一个字符
- with open('test.txt', 'r') as f:
- while True:
- char = f.read(1)
- if not char: break
- print(char, end=' ')
运行结果3.2 每次一行
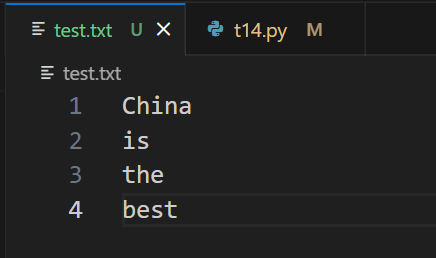
文件内容
- with open('test.txt', 'r') as f:
- while True:
- str = f.readline().strip() # 去掉换行符
- if not str: break
- print(str, end=' ')
- > China is the best
- with open('test.txt', 'r') as f:
- str = f.read()
- print(str, end=' ')
fileinput 可以轻松地处理多个输入流,包括文件、标准输入流等,同时还支持行迭代和缓冲流处理。还可以对大型文件(几个TB)进行处理。
常见的使用方式包括:
- 逐行读取文件中的数据,例如上面提到的例子。
- 处理多个文件,例如通过 glob 模块来指定需要处理的文件列表。
- 实现管道功能,例如通过 subprocess 模块来实现将命令的输出作为输入流来处理。
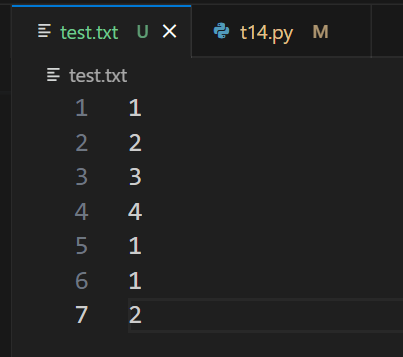
文件内容
- # 逐行读取文件并统计出现次数
- for line in fileinput.input('test.txt'):
- key = line.strip()
- counts[key] = counts.get(key, 0) + 1
- # 输出统计结果
- for key, value in counts.items():
- print(key, '--', value)
免责声明:由于采集信息均来自互联网,如果侵犯了您的权益,请联系我们【E-Mail:cb@itdo.tech】 我们会及时删除侵权内容,谢谢合作! |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
x
|