|
|
一眨眼明天就周末了,一周过的真快!
今天咱们用Python来实现一下动态网页数据的抓取
最近不是有消息说世界首富马上要变成中国人了吗,这要真成了,可就是历史上首位中国世界首富了!
那我们就以富豪排行榜为例,爬取一下2023年国内富豪五百强,最后实现一下可视化分析。
准备工作
环境使用
模块使用
- re 正则表达式
- csv 内置模块 保存数据
- requests >>> 数据请求
- pandas >>> 保存表格
- pyecharts >>> 可视化模块
实现流程:
数据来源分析
- 明确需求: 明确采集的网站以及数据内容
- 目标网址
- 抓包分析: 通过浏览器自带工具 (开发者工具)
- 打开开发者工具: F12 / 右键点检查选择network (网络)
- 点击下一页按钮
数据包地址
代码实现步骤
- 发送请求 -> 模拟浏览器对于url地址发送请求
url地址: 分析找到链接地址
- 获取数据 -> 获取服务器返回响应数据
- 解析数据 -> 提取我们自己需要数据
- 保存数据 -> 保存到表格文件里面
代码解析
发送请求- for page in range(1, 35):
- print(f'{page}' * 20)
- # url地址: 请求网址
- url = f'https://service.ikuyu.cn/XinCaiFu2/pcremoting/bdListAction.do?method=getPage&callback=jsonpCallback&sortBy=assets&order=asc&type=4&keyword=&pageSize=15&year=2023&pageNo={page}&from=jsonp&_=1700739728273'
- # 模拟浏览器: 请求头
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
- }
- # 发送请求: 请求方法 <开发者工具>
- response = requests.get(url=url, headers=headers)
获取数据
解析数据
re.findall(‘匹配数据’, ‘数据源’) -> 从什么地方去获取什么数据- # json字符串数据
- html = re.findall('jsonpCallback\((.*)', data)[0].replace(')', '')
- print(html)
- # 转成json字典 当你转json数据报错的时候 html不是完整json数据格式
- json_data = json.loads(html)
- # 键值对取值 提取 rows 列表 (根据冒号左边的内容[键], 提取冒号右边的内容[值])
- rows = json_data['data']['rows']
- # for循环遍历
- for row in rows:
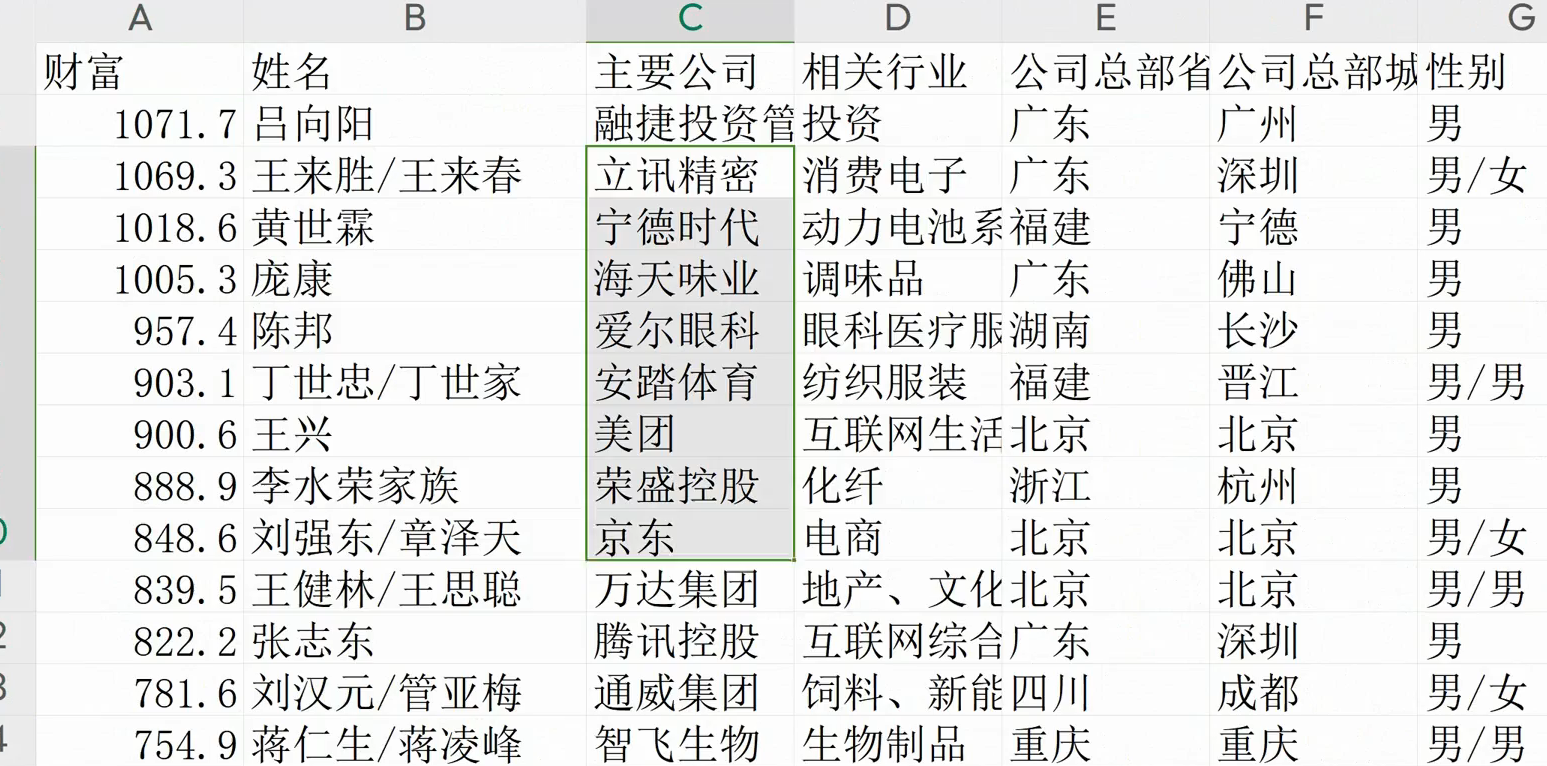
创建文件对象- f = open('data.csv', mode='w', encoding='utf-8', newline='')
- csv_writer = csv.DictWriter(f, fieldnames=[
- '财富',
- '姓名',
- '主要公司',
- '相关行业',
- '公司总部省份',
- '公司总部城市',
- '性别',
- '年龄',
- '年份',
- ])
- csv_writer.writeheader()
保存数据- dit = {
- '财富': row['assets'],
- '姓名': row['name'],
- '主要公司': row['company'],
- '相关行业': row['industry'],
- '公司总部省份': row['addr'][:2],
- '公司总部城市': row['addr'][-2:],
- '性别': row['sex'],
- '年龄': row['age'],
- '年份': row['year'],
- }
- csv_writer.writerow(dit)
- print(row)
- # 源码+wei❤:python1018 领取
采集数据+可视化代码我都打包好了,还有视频讲解,都在最后一段代码中。
效果展示
好了,本次分享就到这结束了,咱们下次见~
来源:https://www.cnblogs.com/hahaa/p/17853925.html
免责声明:由于采集信息均来自互联网,如果侵犯了您的权益,请联系我们【E-Mail:cb@itdo.tech】 我们会及时删除侵权内容,谢谢合作! |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
x
|